本文共 21881 字,大约阅读时间需要 72 分钟。
1.Class类文件结构
Class 文件是一组以 8 位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在 Class 文件之中,中间没有添加任何分隔符,这使得整个 Class 文件中存储的内容几乎全部是程序运行的必要数据,没有空隙存在。
当遇到需要占用 8 位字节以上空间的数据项时,则会按照高位在前(Big-Endian)的方式分割成若干个 8 位字节进行存储。
根据 Java 虚拟机规范的规定,Class 文件格式采用一种类似于 C 语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表,后面的解析都要以这两种数据类型为基础,所以这里要先介绍这两个概念。
无符号数属于基本的数据类型,以 u1、u2、u4、u8 来分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以 “_info” 结尾。表用于描述有层次关系的复合结构的数据,整个 Class 文件本质上就是一张表,它由表 6-1 所示的数据项构成。
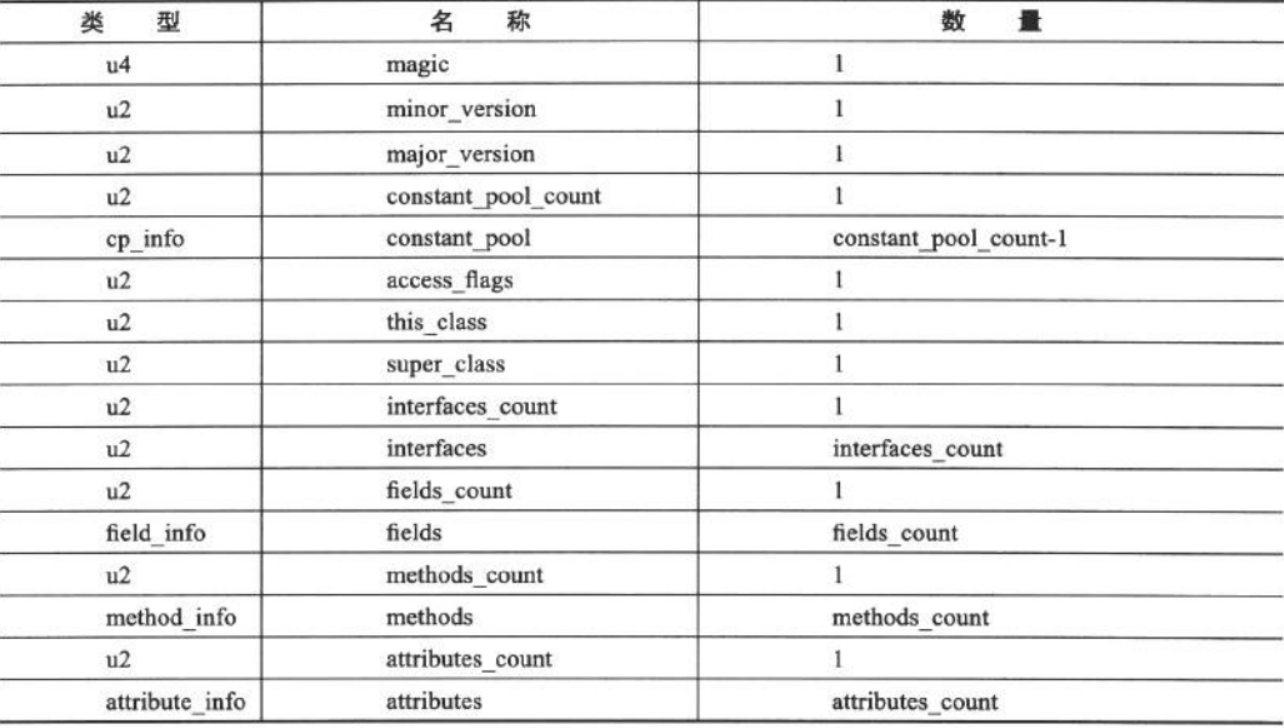
表6-1
无论是无符号数还是表,当需要描述同一类型但数量不定的多个数据时,经常会使用一个前置的容量计数器,加若干个连续的数据项的形式,这时称这一系列的某一类型的数据为某一类型的集合。
Class的结构不像XML等描述语言,由于它没有任何分隔符号,所以在表6-1的数据项,无论是顺序还是数量,甚至于数据存储的字节序(Byte Ordering,Class 文件中字节序为 Big-Endian)这样的细节,
都是被严格限定的,哪个字节代表什么含义,长度是多少,先后顺序如何,都不允许改变。
2.魔数与Class文件的版本
每个Class文件的头4个字节称为魔数,它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。很多文件储存标准中都使用魔数来进行身份识别,譬如图片格式,如 gif 或者 jpeg 等在文件头中都存有魔数。
使用魔数而不是扩展名来仅从识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动。文件格式的制定者额可以自由地选择魔数值,只要这个魔数值还没有被广泛采用过同时又不会引起混淆即可。
Class 文件的魔数的获得很有“浪漫气息”,值为:0xCAFEBABE(咖啡宝贝?),这个魔数值再 Java 还称做“Oak”语言的时候(大约是 1991 年前后)就已经确定下来了。
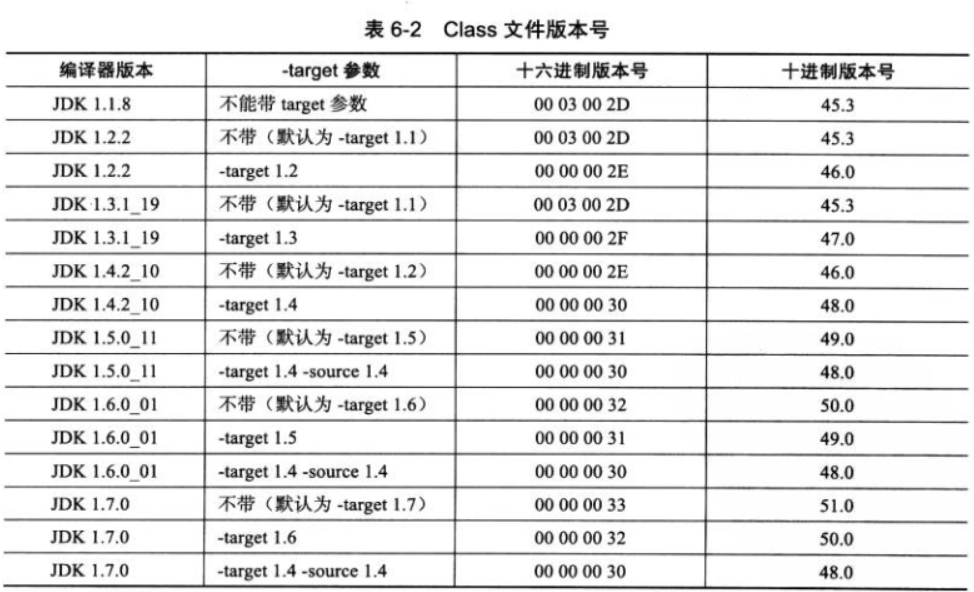
紧接着魔数的4个字节储存的是Class文件的版本号:第5和第6个字节是次版本号,第7和第8个字节是主版本号。Java版本号是从45开始的,JDK1.1之后的每个JDK大版本发布主版本号向上加1(JDK 1.0 ~ 1.1 使用了 45.0 ~ 45.3 的版本号),
高版本的 JDK 能向下兼容以前版本的 Class 文件,但不能运行以后版本的 Class 文件,即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的 Class 文件。
例如,JDK 1.1 能支持版本号为 45.0 ~ 45.65535 的 Class 文件,无法执行版本号为 46.0 以上的 Class 文件,而 JDK 1.2 则能支持 45.0 ~ 46.65535 的 Class 文件。 JDK 版本为 1.7,可生成的 Class 文件主版本号最大值为 51.0.
后面的内容都将以这段小程序使用 JDK 1.6 编译输出的 Class 文件为基础来进行讲解。如下:
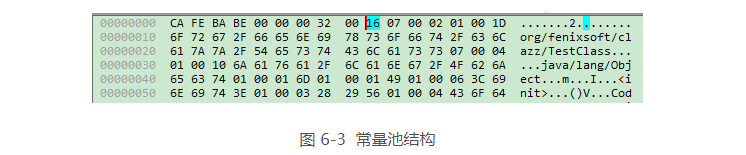
package org.fenixsoft.clazz; public class TestClass { private int m; public int inc() { return m + 1; } } 下图显示的是使用十六进制编辑器WinHex打开这个Class文件的结果,可以清除的看见开头4个字节的十六进制表示是0xCAFEBABE,代表此版本号的第5和第6个字节值为0x0000,而主版本号的值为0x0032,也即十进制的50,
改版本号说明这个文件是可以被JDK1.6或以上版本虚拟机执行的Class文件。

表 6-2 列出了从 JDK 1.1 到 JDK 1.7,主流 JDK 版本编译器输出的默认和可支持的 Class 文件版本号。
3.常量池
紧接着主次版本号之后的是常量池入口,常量池可以理解为Class文件之中的资源仓库,它是Class文件结构中与其他项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,
同时它还是在Class文件中第一个出现的表类型数据项目。
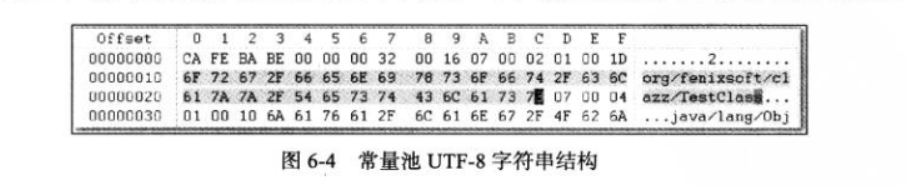
由于常量池中常量的数量是不固定的,所以在常量池的入口需要设置一项u2类型的数据,代表常量池容量计数值。与Java中语言习惯不一样的是,这个容量技术是从1而不是0开始的,如下图表示,常量池容量(偏移地址:0x00000008)
为十六进制数0x0016,即十进制22,这代表常量池中有21项常量,索引值范围为1~21。在Class文件格式规范制定之时,设计者将第0项常量空出来是有特殊考虑的,这样做的目的在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达
"不引用任何一个常量池项目"的含义,这种情况就可以把索引值置为0来表示。Class文件结构中只有常量池的容量计数从1开始,对于其他集合类型,包括接口索引结合,字段表集合,方法表集合等容量技术都与一般习惯相同,从0开始。
常量池主要存放两大类常量:字面量和符号引用。字面量比较接近Java语言层面的常量概念,如文本字符串,声明为final的常量值等。而符号引用则属于编译原理方面的概念,包括了下面三类常量:
1.类和接口的全限定名
2.字段的名称和描述符
3.方法的名称和描述符
Java代码在进行Javac编译的时候,并不像C和C++那样有“连接”这一步骤,而是在虚拟机加载Class文件的时候进行动态连接。也就是说,在Class文件中不会保存各个方法,字段的最终内存布局信息,因此这些字段,方法的符号引用不经过运行期转换的话无法得到真正的内存
入口地址,也就无法直接被虚拟机使用。当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析,翻译到具体的内存地址中。
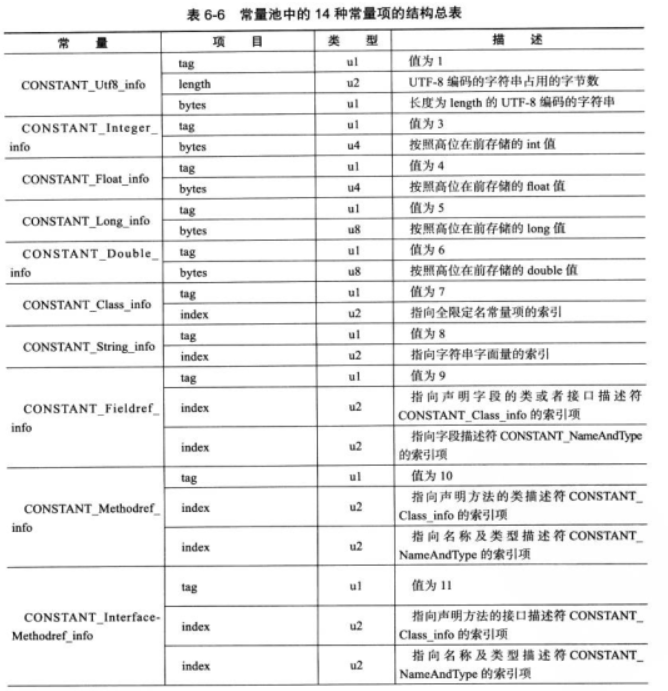
常量池中每一项都是一个表,在JDK1.7之前共有11中结构不相同的表结构数据,在 JDK 1.7 中为了更好地支持动态语言调用,又额外增加了3 种(CONSTANT_MethodHandle_info,CONSTANT_MethodType_info和CONSTANT_InvokeDynamic_info)
这14种表都有一个共同的特点,就是表开始的第一位是一个u1类型的标志位(tag,取值见6-3中标识列),代表当前这个常量属于哪种常量类型。
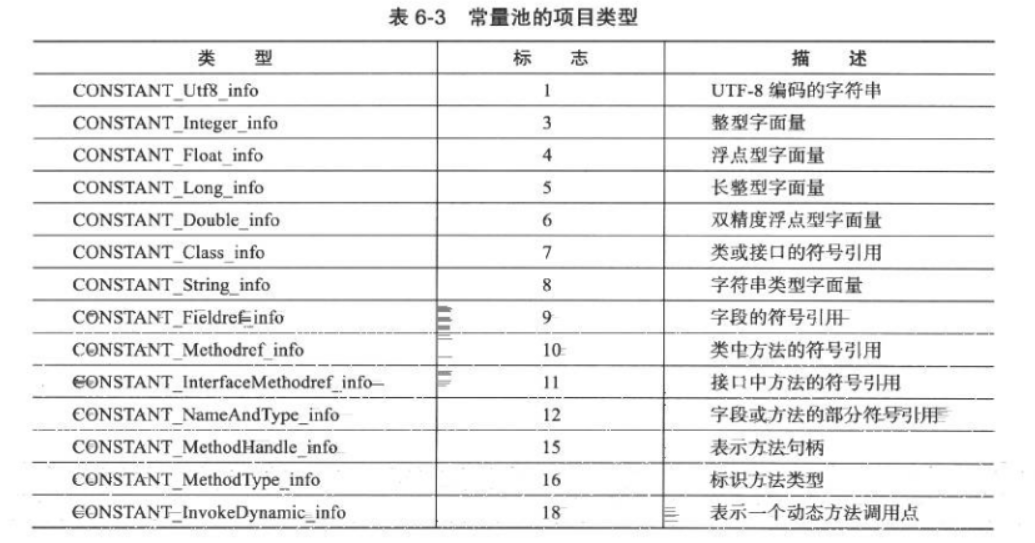
之所以说常量池是最烦锁的数据,是因为这14种常量类型各自有自己的结构。回头看看图 6-3 中常量池的第一项常量,它的标志位(偏移地址:0x0000000A)是 0x07,查表 6-3 的标识列发现这个常量属于 CONSTANT_Class_info 类型,
此类型的常量代表一个类或者接口的符号引用。CONSTANT_Class_info 的结构比较简单,见表 6-4。

tag是标志位,上面已经讲过了,它用于区分常量类型;name_index是一个索引值,它指向常量池中一个CONSTANT_Utf8_info类型常量,此常量代表了这个类(或者接口)的全限定名。这里name_index值(偏移地址:0x0000000B)为 0x0002,
也即是指向了常量池中的第二项常量。继续从图 6-3 中查找第二项常量,它的标志位(地址:0x0000000D)是 0x01,查表 6-3 可知确实是一个 CONSTANT_Utf8_info 类型的常量。CONSTANT_Utf8_info 类型的结构见表 6-5。

length值说明了这个UTF-8编码的字符串长度傻逼多少字节,他后面紧跟着的长度为length字节的连续数据是一个使用UTF-8缩略编码表示的字符串。UTF-8缩略编码与普通UTF-8编码的区别是:
从 '\u0800' 到 '\u07ff' 之间的所有字符的缩略编码用两个字节表示,从 '\u0800' 到 '\uffff' 之间的所有字符的缩略编码接按照普通 UTF-8 编码规则使用三个字节表示。
顺便提一下,由于Class文件中方法,字段等都需要引用CONSTAN_Utf8_info型常量来描述名称,所以CONSTAN_Utf8_info类型常量的最大长度也就是Java方法,字段名的最大长度。而这里的最大长度就是length的最大值,既u2类型能表达的最大值65535.
所以Java程序中如果定义了超过64KB英文字符的变量和方法名,将会无法编译。
本例中这个字符串的length值(偏移地址:0x0000000E)为 0x001D,也就是长 29 字节,往后 29 字节正好都在 1 ~ 127 的 ASCII 码范围以内,内容为 “org/fenixsoft/clazz/TestClass”。一个个字节换算一下,换算结果如下:
到此为止,我们分析了 TestClass.class 常量池中 21 个常量中的两个,其余的 19 个常量都可以通过类似的方法计算出来。为了避免计算过程占用过多的版面,后续的 19 个常量的计算过程可以借助计算机来帮我们完成。
在 JDK 的 bin 目录中,Oracle 公司已经为我们准备好一个专门用于分析 Class 文件字节码的工具:javap,代码清单 6-2 中列出了使用 javap 工具 -verbose 参数输出的 TestClass.class 文件字节码内容(此清单中省略了常量池以为的信息)。
前面我们曾经提到过,Class 文件中还有很多数据项都要引用常量池中的常量,所以代码清单 6-2 中的内容在后续的讲解过程中还要经常使用到。
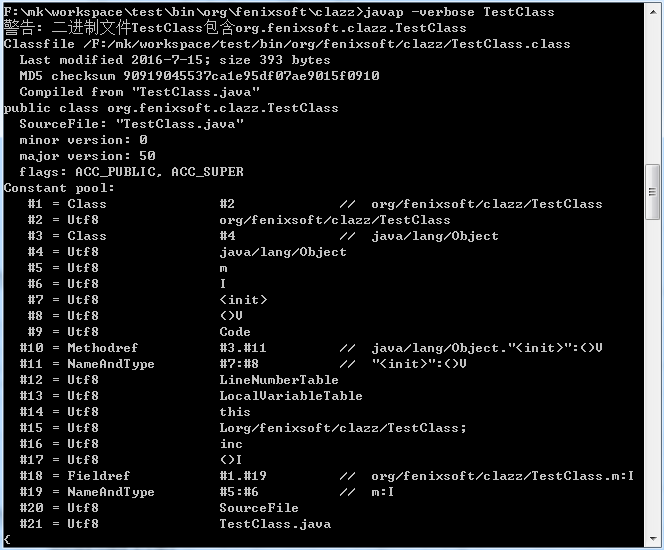
从代码清单6-2中可以看出,计算机已经帮我们把整个常量池的21项常量都计算了出来,并且第1,2项常量的计算结果与我们手工计算的结果一致,仔细一看会发现,其中有一些常量似乎从你过来没有在代码中出现过,
如“I”、“V”、“<init>”、“LineNumberTable”、“LocalVariableTable”等,这些看起来在代码任何一处都没有出现过的常量是哪里来的呢?
这部分自动生成的常量的确没有在Java代码里面直接出现过,但它们会被后面即将讲到的字段表(field_info)、方法表(method_info)、属性表(attribute_info)引用到,它们会用来描述一些不方便使用“固定字节”进行
表达的内容。譬如描述方法的返回值是什么?有几个参数?每个参数的类型是什么?因为Java中的类是无穷无尽的,无法通过简单的无符号字节来描述一个方法用到了什么类,因此,在描述方法的这些信息时,需要引用常量表中的
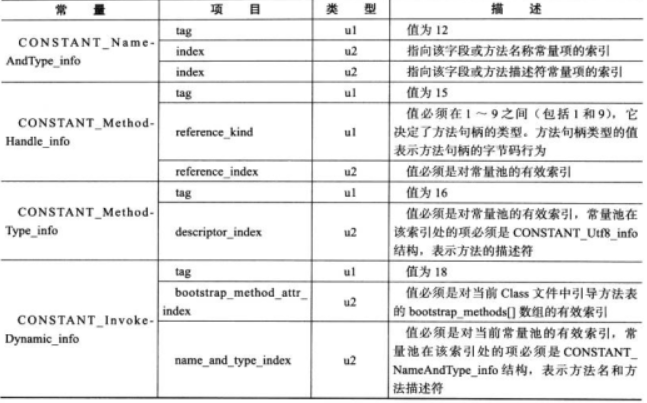
符号引用进行表达。这部分内容将在后面进行一步阐述。这 14 种常量项的结构定义总结为表 6-6 以供读者参考。
4.访问标志
在常量池结束之后,紧接着的两个字节代表访问标志(access_flags),这个标志用于识别一些类或接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstrack类型;如果是类的话,
是否被声明为final等。具体的标志位以及标志的含义见表 6-7。
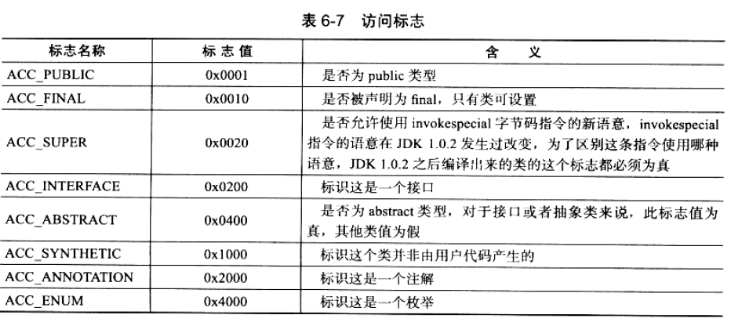
access_flags 中一共有 16 个标志位可以使用,当前只定义了其中 8 个(注:在 Java 虚拟机规范中,只定义了开头 5 种标志。JDK 1.5 中增加了后面三种。这些标志位在 JSR-202 规范中声明。),
没有使用到的标志位要求一律为 0。以代码清单 6-1 中的代码为例,TestClass 是一个普通 Java 类,不是借口、枚举或者注解,被 public 关键字修饰但没有被声明 final 和 abstract,并且它使用了 JDK 1.2 之后的编译器进行编译,
因此它的 ACC_PUBLIC、ACC_SUPER 标志应当为真,而 ACC_FINAL、ACC_INTERFACE、ACC_ABSTRACT、ACC_SYNTHETIC、ACC_ANNOTATION、ACC_ENUM 这 6 个标志应当为假,
因此它的 access_flags 值应为:0x0001 | 0x0020 = 0x0021。从图 6-5 中可以看出,access_flags 标志(偏移地址:0x000000EF)的确为 0x0021。
5.类索引,父索引与接口索引集合
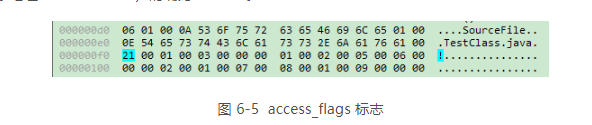
类索引(this_class)和父类索引(super_class)都是一个u2 类型的数据,而接口索引集合(interfaces)是一组 u2 类型的数据的集合,Class文件中由这三项数据来确定这个类的继承关系。类索引用于确定这个类的全限定名,
父类索引用于确定这个类的弗雷的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了java.lang.Object 外,所有 Java 类的父类索引都不为 0。接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口就按implements语句
(如果这个类本身是一个接口,则应当是 extends 语句)后的接口顺序从左到右排列在接口索引集合中。
类索引,父类索引和接口索引集合都按照顺序排列在访问标志之后,类索引和父类索引用两个u2类型的索引值表示,它们各自指向一个类型为CONSTANT_Class_info的类描述符常量,通过CONSTANT_Class_info类型的常量中的索引值可以
找到定义在CONSTAN_Utif8_info类型的常量中的全限定名字符串。图6-6表演了上面代码的类索引查找过程。
对于接口索引集合,入口的第一项——u2类型的数据为接口计数器表示索引表的容量。如果该类没有实现任何接口,则该技术值为0,后面接口的索引表不再占用任何字节。代码清单6-1中的代码的类索引,父类索引与接口表索引的内容如图6-7所以
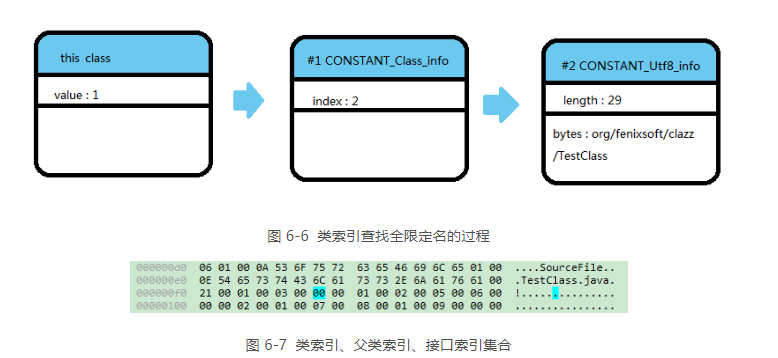
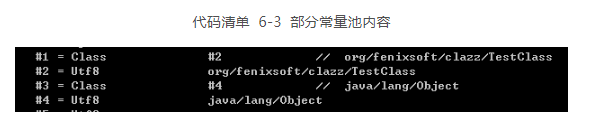
从偏移量地址0x000000F1 开始的 3 个 u2 类型的值分别为 0x0001、0x0003、0x0000,也就是类索引为 1,父类索引为 3,接口索引集合大小为 0,查询前面代码清单 6-2 中 javap 命令计算出来的常量池,找出对应的类和父类的常量,结果如代码清单 6-3 所示。
6.字段表集合
字段表(field_info)用于描述接口或者类中声明的变量。字段(field)包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。我们可以想一想在 Java 中描述一个字段可以包含什么信息?
可以包括的信息有:字段的作用域(public、private、protected 修饰符)、是实例变量还是类变量(static 修饰符)、可变性(final)、并发可见性(volatile 修饰符,是否强制从主内存读写)、可否被序列化(transient 修饰符)、字段数据类型(基本类型、对象、数组)、字段名称。
上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述。表 6-8 中列出了字段表的最终格式。
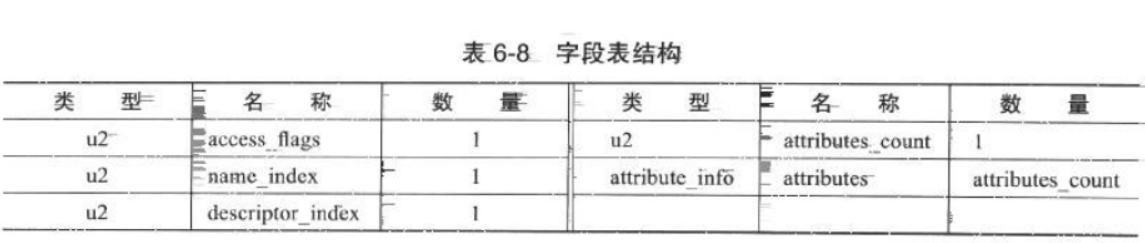
字段修饰符放在access_flags 项目中,它与类中的 access_flags 项目是非常类似的,都是一个 u2 的数据类型,其中可以设置的标志位和含义见表 6-9。
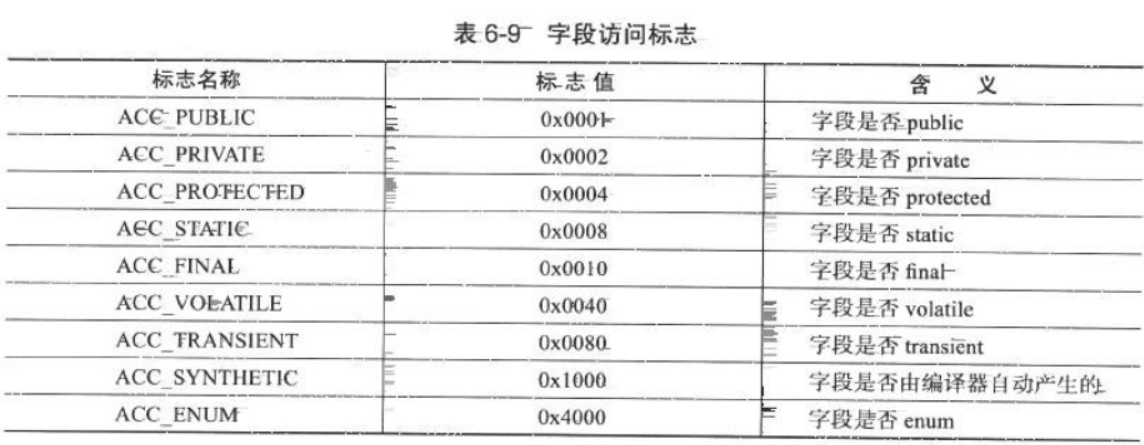
很明显,在实际情况中,ACC_PUBLIC、ACC_PRIVATE、ACC_PROTECTED 三个标志最多只能选择其一,ACC_FINAL、ACC_VOLATILE 不能同时选择。接口之中的字段必须有 ACC_PUBLIC、ACC_STATIC、ACC_FINAL 标志,这些都是由 Java 本身的语言规则所决定的。
跟随access_flags标志的是两项索引值:name_index和descriptor_index。它们都是对常量池的引用,分别代表着字段的简单名称以及字段和方法的描述符。现在需要解释一下“简单名称”、“描述符”以及前面出现过多次的“全限定名”这三种特殊字符串的概念。
全限定名和简单名称很好理解,以代码清单6-1中的代码为例,“org/fenixsoft/clazz/TestClass”是这个类的全限定名,仅仅是把类全名中的“.”替换成了“/”而已,为了使连续的多个全限定名之间不产生混淆,在使用时最后一般会加入一个";"表示全限定名结束。
简单名称是指没有类型和参数修饰的方法或者字段名称,这个类中的inc()方法和m字段的简单名称分别是inc和m
相对于全限定名和简单名称来说,方法和字段的描述符就要复杂一些。描述符的作用是用来描述字段的数据类型,方法的参数列表(包括数量,类型以及顺序)和返回值。
根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的 void 类型都用一个大写字符来表示,而对象类型则用字符 L加对象的全限定名来表示,详见表 6-10。
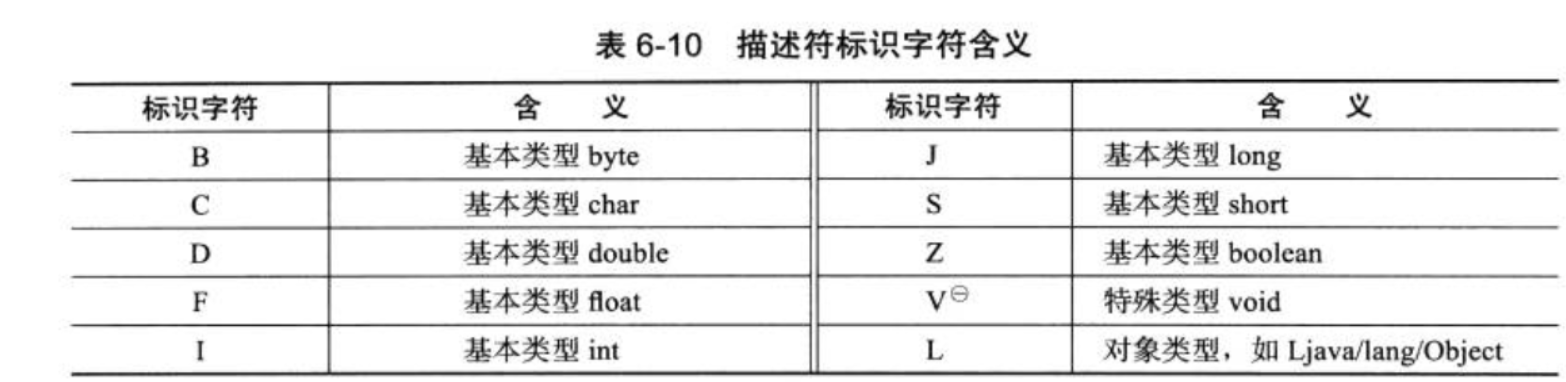
对于数组类型,每一维度将使用一个前置的“[”字符来描述,如一个定义为“java.lang.String[][]” 类型的二维数组,将被记录为:“[[Ljava/lang/String;”,一个整型数组 “int[]” 将被记录为 “[I”。
用描述符来描述方法时,按照先参数列表,后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法void inc()的描述符为“()V”,
方法 java.lang.String toString() 的描述符为 “()Ljava/lang/String;”,方法 int indexOf(char[] source, int sourceOffset, int sourceCount, char[]target, int targetOffset, int targetCount, int fromIndex)的描述符为 “([CII[CIII)I”。
对于代码清单 6-1 中的 TestClass.class 文件来说,字段表集合从地址 0x000000F8 开始,第一个 u2 类型的数据为容量计数器 fields_count,如图 6-8 所示。其值为 0x0001,说明这个类只有一个字段表数据。
接下来紧跟着容量计数器的是 access_flags 标志,值为 0x0002,代表 private 修饰符的 ACC_PRIVATE 标志位为真(ACC_PRIVATE 标志的值为 0x0002),其他修饰符为假。代表字段名称的 name_index 的值为 0x0005,
从代码清单 6-2 列出的常量表中可查得第 5 项常量是一个 CONSTANT_Utf8_info 类型的字符串,其值为“m”,代表字段描述符的 descriptor_index 的值为 0x0006,指向常量池的字符串“I”,根据这些信息,我们可以推断出原代码定义的字段为:“private int m;”。
字段表都包含的固定数据项目到 descriptor_index 为止就结束了,不过在 descriptor_index 之后跟随着一个属性表集合用于存储一些额外的信息,字段都可以在属性表中描述零至多项的额外信息。
对于本例中的字段 m,它的属性表计数器为 0,也就是没有需要额外描述的信息,但是,如果将字段 m 的声明改为 “final static int m=123;”,那就可能会存在一项名称为 ConstantValue 的属性,其值指向常量 123。

字段表集合中不会列出从超类或者父接口中继承而来的字段,但有可能列出原本 Java 代码之中不存在的字段,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
另外,在 Java 语言中字段是无法被重载的,两个字段的数据类型、修饰符不管是否相同,都必须使用不一样的名称,但是对于字节码来将,如果两个字段的描述符不一致,那字段重名就是合法的。
7.方法集合
如果理解了上面字段表的内容,那么方法表的内容将会变得很简单。Class文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式,
方法表的结构如同字段表一样依次包括了访问标志(access_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)几项,见表 6-11。这些数据项目的含义也非常类似,仅在访问标志和属性表集合的可选项中有所区别。

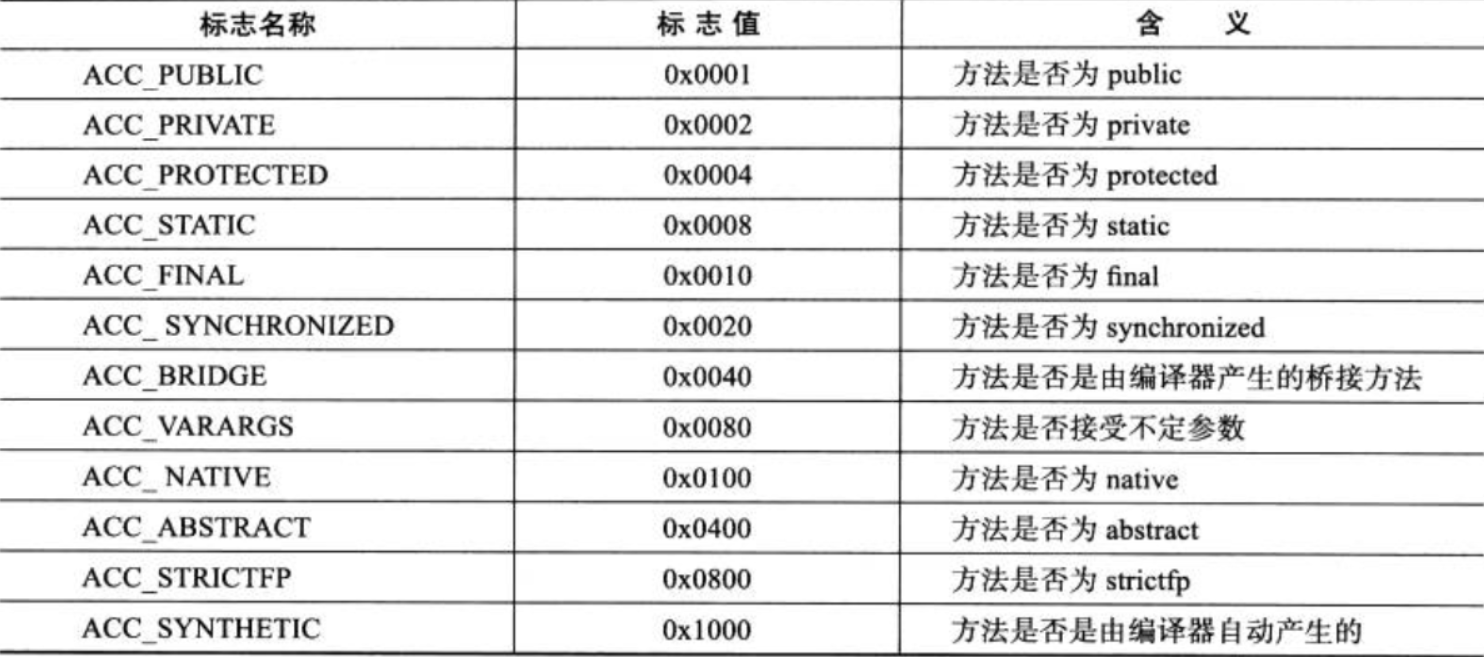
因为volatile关键字和transient关键字不能修饰方法,所以方法表的访问标志中没有了ACC_VOLATILE标志和ACC_TRANSIENT标志。与之相对的,synchronized、native、strictfp 和 abstract 关键字可以修饰方法,
所以方法表的访问标志中增加了 ACC_SYNCHRONIZED、ACC_NATIVE、ACC_STRICTFP 和 ACC_ABSTRACT 标志。对于方法表,所有标志位及其取值可参见表 6-12。
行文至此,也许会产生疑问,方法的定义可以通过访问标志、名称索引、描述符索引表达清楚,但方法里面的代码去哪里了?方法里的 Java 代码,经过编译器编译成字节码指令后,
存放在方法属性表集合中一个名为 “Code” 的属性里面,属性表作为 Class 文件格式中最具扩展性的一种数据项目,将在下一节(属性表集合)中详细讲解。
继续以上面的代码清单中的Class文件为例对方法集合进行分析,如6-9所示,方法集合的入口地址为0x00000101,第一个u2类型的数据(即是计数器容量)的值为0x0002,代表集合中有两个方法(这两个方法为编译器添加的实例构造<init>和源码中的方法inc())。
第一个方法的访问标志值为 0x0001,也就是只有 ACC_PUBLIC 标志为真,名称索引值为 0x0007,查代码清单 6-2 的常量池得方法名为“<init>”,描述符索引值为 0x0008,对应常量为“()V”,属性表计数器 attributes_count 的值为 0x0001 就表示此方法的属性表集合有一项属性,属性名称索引为 0x0009,对应常量为“Code”,说明此属性是方法的字节码描述。
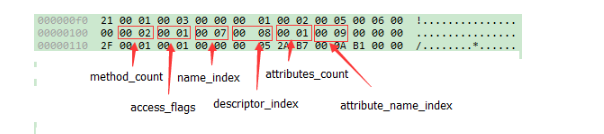
与字段表集合相对应的,如果父类方法在子类中没有被重写,方法集合中就不会出现来自父类的方法信息。但同样的,有可能会出现由编译器自动添加的方法,最经型的便是类构造器"<clinit>"方法和实例构造器“<init>”方法。
在 Java 语言中,要重载(Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名(注:Java 代码的方法特征签名只包括方法名称、参数顺序及参数类型,而字节码的特征签名还包括方法返回值以及受查异常表),特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,也就是因为返回值不会包含在特征签名中,因此 Java 语言里面是无法仅仅依靠返回值的不同来对一个已有方法进行重载的。但是在 Class 文件格式中,特征签名的范围更大一些,只要描述符不是完全一致的两个方法也可以共存。也就是说,如果两个方法有相同的名称和特征签名,但返回值不同,那么也是可以合法共存于同一个 Class 文件中的。
8.属性表集合
属性表(attribute_info)在前面的讲解之中已经出现过数次,在 Class 文件、字段表、方法表都可以携带子机的属性表集合,以用于描述某些场景专有的信息。
与 Class 文件中其他的数据项目要求严格的顺序、长度和内容不同,属性表集合的限制稍微宽松了一些,不再要求各个属性表具有严格顺序,并且只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,
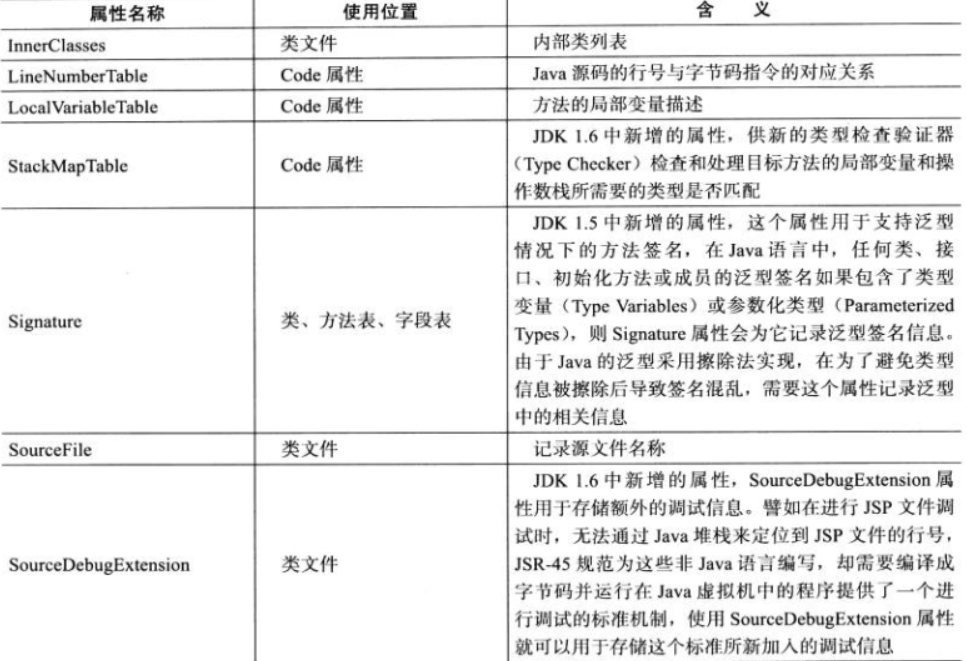
Java 虚拟机运行时会忽略掉它不认识的属性。为了能正确解析 Class 文件,《Java 虚拟机规范(第 2 版)》中预定义了 9 项虚拟机实现应当能识别的属性,而在最新的《Java 虚拟机规范(Java SE 7)》版中,
预定义属性已经增加到 21 项,具体内容见表 6-13。下文中将对其中一些属性中的关键常用的部分进行讲解。
6-13
对于每个属性,它的名称需要从常量池中引用一个 CONSTANT_Utf8_info 类型的常量来表示,而属性值的结构则是完全自定义的,只需要通过一个 u4 的长度属性去说明属性值所占用的位数即可。一个符合规则的属性表应该满足表 6-14 中所定义的结构。

9.Code属性
Java程序方法体中的代码经过Javac编译器处理后,最终变为字节码指令存储在Code属性内。Code属性出现在方法表的属性集合中,但并非所有的方法都不许存在这个属性,譬如接口或者抽象类中的方法就不存在Code属性,如果
方法表有Code属性存在,那么它的结构如表6-15所示。
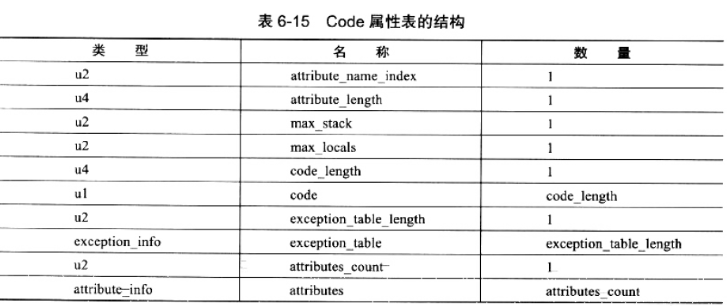
attribute_name_index 是一项指向 CONSTANT_Utf8_info 型常量的索引,常量值固定为“Code”,它代表了该属性的属性名称,attribute_length 指示了属性值的长度,由于属性名称索引与属性长度一共为 6 字节,所以属性值的长度固定为整个属性表长度减去 6 个字节。
max_stack 代表了操作数栈(Operand Stacks)深度的最大值。在方法执行的任意时刻,操作数栈都不会超过这个深度。虚拟机运行的时候需要根据这个值来分配栈帧(Stack Frame)中的操作栈深度。
max_locals 代表了局部变量表所需的存储空间,在这里,max_locals 的单位是 Slot,Slot 是虚拟机为局部变量分配内存所使用的最小单位。对于 byte、char、float、int、short、boolean 和 returnAddress 等长度不超过 32 位的数据类型,每个局部变量占用 1 个 Slot,
而 double 和 long 这两种 64 位的数据类型则需要两个 Slot 来存放。方法参数(包括实例方法中的隐藏参数 “this”)、显式异常处理器的参数(Exception Handler Parameter,就是 try-catch 语句中 catch 块所定义的异常)、方法体中定义的局部变量都需要使用局部变量表来存放。
另外,并不是在方法中用到了多少个局部变量,就把这些局部变量所占 Slot 之和作为 max_locals 的值,原因是局部变量表中的 Slot 可以重写,当代码执行超出一个局部变量的作用域时,这个局部变量所占的 Slot 可以被其他局部变量所使用,
Javac 编译器会根据变量的作用域来分配 Slot 给各个变量使用,然后计算出 max_locals 的大小。
code_length 和 code 用来存储 Java 源程序编译后生成的字节码指令。code_length 代表字节码长度,code 是用于存储字节码指令的一系列字节流。既然叫字节码指令,那么每个指令就是一个 u1 类型的单字节,当虚拟机读取到 code 中的一个字节码时,
就可以对应找出这个字节码代表的是什么指令,并且可以知道到这条指令后面是否需要跟随参数,以及参数应当如何理解。我们知道一个 u1 数据类型的取值范围为 0x00 ~ 0xFF,对应十进制的 0 ~ 255,也就是一共可以表达 256 条指令,目前,Java 虚拟机规范已经定义了其中约 200 条编码值对应的指令含义。
关于 code_length,有一件值得注意的事情,虽然它是一个 u4 类型的长度值,理论上最大值可以达到 2^23-1,但是虚拟机规范中明确限制了一个方法不允许超过65535 条字节码指令,即它实际只使用了 u2 的长度,如果超过这个限制,Javac 编译器也会拒绝编译。一般来讲,编写 Java 代码时只要不是刻意去编写一个超长的方法来为难编译器,是不太可能超过这个最大值的限制。但是,某些特殊情况,例如在编译一个很复杂的 JSP 文件时,某些 JSP 编译会把 JSP 内容和页面输出的信息归并于一个方法之中,就可能因为方法生成字节码超长的原因而导致编译失败。
Code 属性是 Class 文件中最重要的一个属性,如果把一个 Java 程序中的信息分为代码(Code,方法体里面的 Java 代码)和元数据(Metadata,包括类、字段、方法定义及其他信息)量部分,那么在整个 Class 文件中,Code 属性用于描述代码,所有的其他数据项目都用于描述元数据。了解 Code 属性是学习后面关于字节码执行引擎内容的必要基础,能直接阅读字节码也是工作中分析 Java 代码语义问题的必要工具和基本技能,因此笔者准备了一个比较详细的实例来讲解虚拟机是如何使用这个属性的。
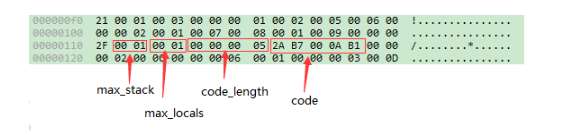
继续以代码清单 6-1 的 TestClass.class 文件为例,如图 6-10 所示,这是上一节分析过的实例构造器“<init>”方法的 Code 属性。它的操作数栈的最大深度和本地变量表的容量都为 0x0001,字节码区域所占空间的长度为 0x0005。虚拟机读取到字节码区域的长度后,按照顺序依次读入紧随的 5 个字节,并根据字节码指令表翻译出所对应的字节码指令。翻译“2A B7 00 0A B1”的过程为:
- 读入 2A,查表得 0x2A 对应的指令为 aload_0,这个指令的含义是将第 0 个 Slot 中为 reference 类型的本地变量推送到操作数栈顶。
- 读入 B7,查表得 0xB7 对应的指令为 invokespecial,这条指令的作用是以栈顶的 reference 类型的数据所指向的对象作为方法接受者,调用此对象的实例构造器方法、private 方法或者它的父类的方法。这个方法有一个 u2 类型的参数说明具体调用哪一个方法,它指向常量池中的一个 CONSTANT_Methodref_info 类型常量,即此方法的方法符号引用。
- 读入 00 0A,这是一 invokespecial 的参数,查常量池得 0x000A 对应的常量为实例构造器“<init>”方法的符号引用。
- 读入 B1,查表得 0xB1 对应的指令为 return,含义是返回此方法,并且返回值为 void。这条指令执行后,当前方法结束。
这段字节码虽然很短,但是至少可以看出它的执行过程中的数据交换、方法调用等操作都是基于栈(操作栈)的。我们可以初步猜测:Java 虚拟机执行字节码是基于栈的体系结构。但是与一般基于堆栈的零字节指令又不太一样,某些指令(如 invokespecial)后面还会带有参数。
我们再次使用 javap 命令把此 Class 文件中的另外一个方法的字节码指令也计算出来,结果如代码清单 6-4 所示。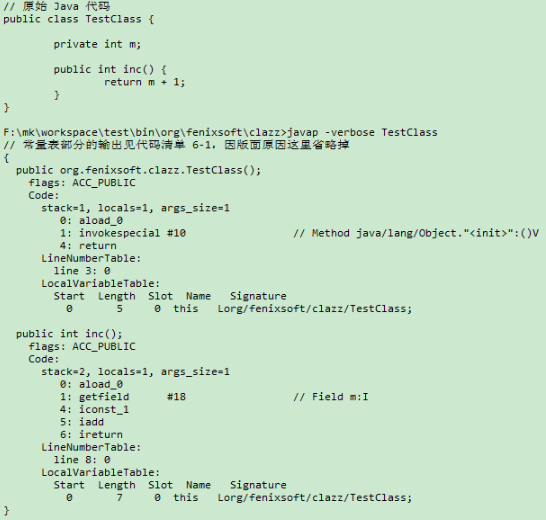
如果大家注意到 javap 中输出的 “args_size”的值,可能会有疑问:这个类有两个方法——实例构造器<init>() 和 inc(),这两个方法很明显都是没有参数的,为什么 args_size 会为 1?而且无论是在参数列表里还是方法体内,都没有定义任何局部变量,
那 Locals 又为什么会等于1?如果有这样的疑问,大家可能是忽略了一点:在任何实例方法里面,都可以通过“this” 关键字访问到此方法所属的对象。这个方法机制对 Java 程序的编写很重要,而它的实现却非常简单,
仅仅是通过 javac 编译器编译的时候把对 this 关键字的访问转变为对一个普通方法参数的访问,然后在虚拟机调用实例方法时自动传入此参数而已。因此在实例方法的局部变量表中至少会存在一个指向当前对象实例的局部变量,
局部变量表中也会预留出第一个 Slot 位来存放对象实例的引用,方法参数值从 1 开始计算。这个处理只对实例方法有效,如果代码清单 6-1 中的 inc() 方法声明为 static,那 args_size 就不会等于 1 而是等于 0 了。
在字节码指令之后的是这个方法显示异常处理表(下文简称异常表)集合,异常表对于 Code 属性来说并不是必须存在的,如代码清单 6-4 中就没有异常表生成。
异常表的格式如表 6-16 所示,它包含 4 个字段,这些字段的含义为:如果当字节码在第 start_pc 行(注:此处字节码的 “行” 是一种形象的描述,指的是字节码相对于方法体开始的偏移量,而不是 Java 源码的行号)到第 end_pc 行之间(不含第 end_pc 行)出现了类型为 catch_type 或者其子类的异常(catch_type 为指向一个 CONSTANT_Class_info 型常量的索引),则转到第 handler_pc 行继续处理。当catch_type的值为 0时,代表任意异常情况都需要转向到 handler_pc 处进行处理。

异常表实际上是 Java 代码的一部分,编译器使用异常表而不是简单的跳转命令来实现Java 异常及 finally 处理机制。
代码清单 6-5 是一段演示异常表如何运作的例子,这段代码主要演示了在字节码层面中 try-catch-finally 是如何实现的。在阅读字节码之前,大家不妨先看看下面的 Java 源码,想一下这段代码的返回值在出现异常和不出现异常的情况下分别应该是多少?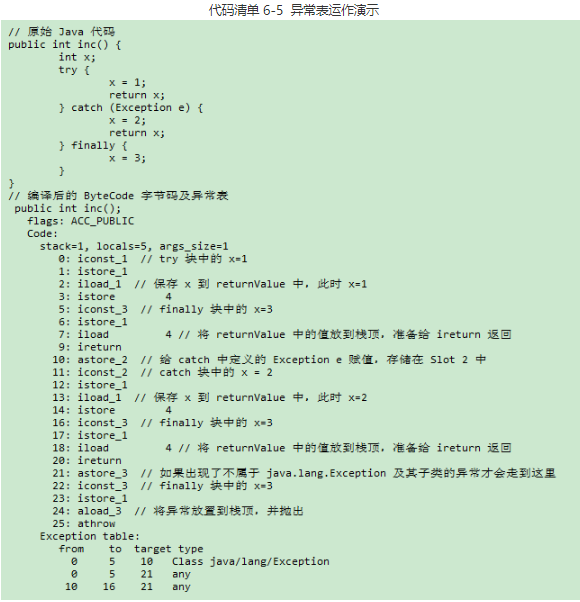
编译器为这段 Java 源码生成了 3 条异常表记录,对应 3 条可能出现的代码执行路径。从 Java 代码的语义上讲,这 3 条执行路径分别为:
- 如果 try 语句块中出现属于 Exception 或其子类的异常,则转到 catch 语句块处理。
- 如果 try 语句块中出现不属于 Exception 或器子类的异常,则转到 finally 语句块处理。
- 如果 catch 语句块中出现任何异常,则转到 finally 语句块处理。
返回到我们上面提出的问题,这段代码的返回值应该是多少?对 Java 语言熟悉的读者应该很容易说出答案:如果没有出现异常,返回值是 1;如果出现了 Exception 异常,返回值是 2;如果出现了 Exception 以外的异常,方法非正常退出,没有返回值。我们一起来分析一下字节码的执行过程,从字节码的层面上看看为何会有这样的返回结果。
字节码中第 0 ~ 4 行所做的操作就是将整数 1 赋值非变量 x,并且将此时 x 的值复制一份副本到最后一个本地变量表的 Slot 中(这个 Slot 里面的值在 ireturn 指令执行前将会被重新读到操作栈顶,作为方法返回值使用。为了讲解方便,笔者给这个 Slot 起了个名字:returnValue)。如果这时没有出现异常,则会继续走到第 5~9 行,将变量 x 赋值为 3,然后将之前保存在 returnValue 中的整数 1 读入到操作栈顶,最后 ireturn 指令会以 int 形式返回操作栈顶的 值,方法结束。如果出现了异常,PC 寄存器指针转到第 10 行,第 10 ~ 20 行所做的事情是将 2 赋值给变量 x,然后将变量 x 此时的值赋给 returnValue,最后再将变量 x 的值改为 3。方法返回前同样将 returnValue 中保留的整数 2 读到了操作栈顶。从第 21 行开始的代码,作用是变量 x 的值复位 3,并将栈顶的异常抛出,方法结束。 尽管大家都知道这段代码出现异常的概率非常小,但并不影响我们演示异常表的作用。10.Exception属性
这里的 Exceptions 属性是在方法表中与 Code 属性平级的一项属性,读者不要与前面刚刚讲解完的异常表产生混淆。Exceptions 属性的作用是列举出方法中可能抛出的受检查异常(Checked Exceptions),也就是方法描述时在 throws 关键字后面列举的异常。它的结构见表 6-17。

11.LineNumberTable属性
LineNumberTable 属性用于描述 Java 源码行号与字节码行号(字节码的偏移量)之间的对应关系。它并不是运行时必需的属性,但默认会生成到 Class 文件之中,可以在 javac 中分别使用 -g:none 或 -g:lines 选项来取消或要求生成这项信息。如果选择不生成LineNumberTable 属性,对程序运行产生的最主要的影响就是当抛出异常时,堆栈中将不会显示出错的行号,并且在调试程序的时候,也无法按照源码行来设置断点。LineNumberTable 属性的结构见表 6-18。
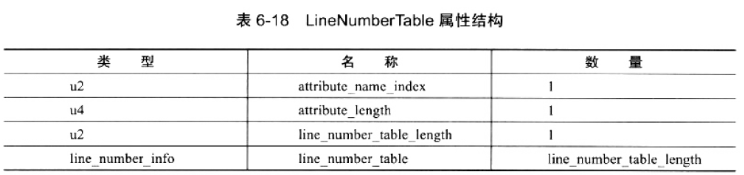
line_number_table 是一个数量为 line_number_table_length、类型为 line_number_info 的集合,line_number_info 表包括了 start_pc 和 line_number 两个 u2 类型的数据项,前者是字节码行号,后者是 Java 源码行号。
12.LocalVariableTable属性
LocalVariableTable 属性用于描述栈帧中局部变量表中的变量与 Java 源码中定义的变量之间的关系,它也不是运行时必需的属性,但默认会生成到 Class 文件之中,可以在 Javac 中分别使用 -g:none 或 -g:vars 选项来取消或要求生成这项信息。如果没有生成这项属性,最大的影响就是当其他人引用这个方法时,所有的参数名称都将会丢失,IDE 将会使用诸如 arg0、arg1 之类的占位符代替原有的参数名,这对程序运行没有影响,但是会对代码编写带来较大不变,而且在调试期间无法根据参数名称从上下文获得参数值。LocalVariableTable 属性的结构见表 6-19。
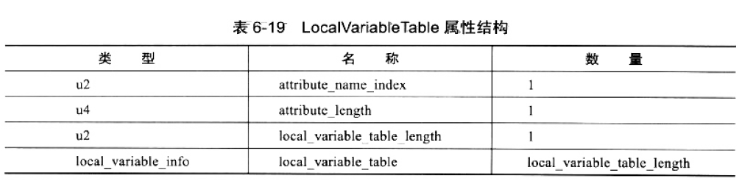
其中,local_variable_info 项目代表了一个栈帧与源码中的局部变量的关联,结构见表 6-20

start_pc 和 length 属性分别代表了这个局部变量的生命周期开始的字节码偏移量及其作用范围覆盖的长度,两者结合起来就是这个局部变量在字节码之中的作用域范围。
name_index 和 descriptor_index 都是指向常量池中 CONSTANT_Utf8_info 型常量的索引,分别代表了局部变量的名称以及这个局部变量的描述符。
index 是这个局部变量在栈帧局部变量表中 Slot 的位置。当这个变量数据类型是 64 位类型时(double 和 long),它占用的 Slot 为 index 和 index+1 两个。
顺便提一下,在 JDK 1.5 引入泛型之后,LocalVariableTable 属性增加了一个 “姐妹属性”:LocalVariableTypeTable,这个新增的属性结构与 LocalVariableTable 非常相似,仅仅是把记录的字段描述符的 descriptor_index 替换成了字段的特征签名(Signature),
对于非泛型类型来说,描述符和特征签名能描述的信息是基本一致的,但是泛型引入之后,由于描述符中泛型的参数化类型被擦除掉,描述符就不能准确地描述泛型类型了,因此出现了 LocalVariableTypeTable。
12.SourceFile属性
SourceFile 属性用于记录生成这个 Class 文件的源码文件名称。这个属性也是可选的,可以分别使用 javac 的 -g:none 或 -g:source 选项来关闭或要求生成这项信息。在 Java 中,对于大多数的类来说,类名和文件名是一致的,但是又一些特殊情况(如内部类)例外。如果不生成这项属性,当抛出异常时,堆栈中将不会显示出错代码所属的文件名。这个属性是一个定长的属性,其结构见表 6-21。

sourcefile_index 数据项是指向常量池中 CONSTANT_Utf8_info 型常量的索引,常量值是源码文件的文件名。
13.ConstantValue属性
ConstantValue 属性的作用是通知虚拟机自动为静态变量赋值。只有被 static 关键字修饰的变量(类变量)才可以使用这项属性。类似 “int x = 123” 和 “static int x = 123” 这样的变量定义在 Java 程序中是非常常见的事情,但虚拟机对这两种变量赋值的方式和时刻都有所不同。对于非 static 类型的变量(也就是实例变量)的赋值是在实例构造器 <init> 方法中进行的;而对于类变量,则有两种方式可以选择:在类构造器 <clinit> 方法中或者使用 ConstantValue 属性。目前 Sun Javac 编译器的选择是:如果同时使用 final 和 static 来修饰一个变量(按照习惯,这里称 “常量” 更贴切),并且这个变量的数据类型是基本类型或者 java.lang.String 的话,就生成 ConstantValue 属性来进行初始化,如果这个变量没有被 final 修饰,或者并非基本类型及字符串,则将会选择在 <clinit> 方法中进行初始化。
虽然有 final 关键字 才更符合 “ConstantValue” 的语义,但虚拟机规范中并没有强制要求字段必须设置了 ACC_FINAL 标志,只要求了有 ConstantValue 属性的字段必须设置 ACC_STATIC 标志而已,对 final 关键字的要求是 javac 编译器自己加入的限制。而对 ConstantValue 的属性值只能限于基本类型和 String,不过笔者不认为这是什么限制,因为此属性值只是一个常量池的索引号,由于 Class 文件格式的常量类型中只有与基本属性和字符串相对应的字面量,所以就算 ConstantValue 属性想支持别的类型也无能为力。ConstantValue 属性的结构见表 6-22。

从数据结构中可以看出,ConstantValue 属性是一个定长属性,它的 attribute_length 数据项值必须固定为 2。constantvalue_index 数据项代表了常量池中一个字面量常量的引用,根据字段类型的不同,字面量可以是CONSTANT_Long_info、CONSTANT_Float_info、CONSTANT_Double_info、CONSTANT_Integer_info、CONSTANT_String_info常量中的一种。
14.InnerClass属性
InnerClass 属性用于记录内部类与宿主类之间的关联。如果一个类中定义了内部类,那编译器将会为它以及它所包含的内部类生成 InnerClass 属性。该属性的结构见表 6-23。
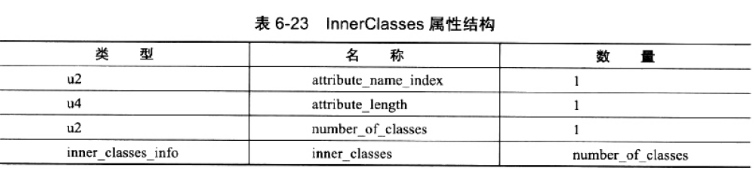
数据项 number_of_classes 代表需要记录多少个内部类信息,每一个内部类的信息都由一个 inner_classes_info 表进行描述。inner_classes_info 表的结构见表 6-24。
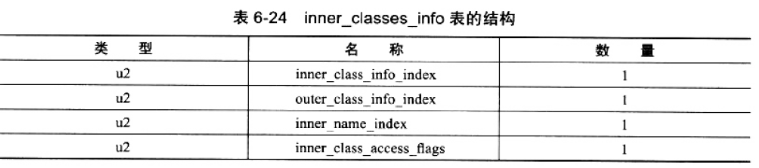
inner_class_info_index 和 outer_class_info_index 都是指向常量池中 CONSTANT_Class_info 型常量的索引,分别代表了内部类和宿主类的符号引用。
inner_name_inex 是指向常量池中 CONSTANT_Utf8_info 型常量的索引,代表这个内部类的名称,如果是匿名内部类,那么这项值为 0。
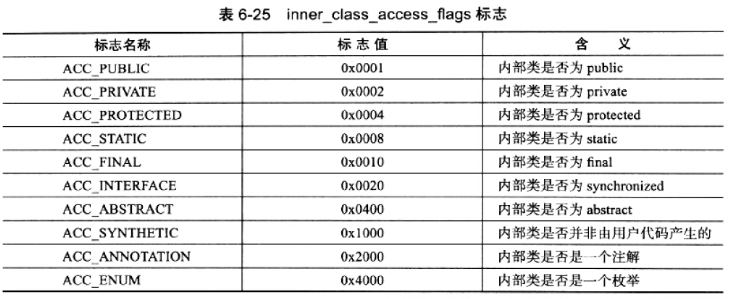
inner_class_access_flags 是内部类的访问标志,类似于类的 access_flags,它的取值范围见表 6-25。
15.Deprecated及Synthetic属性
Deprecated 和 Synthetic 两个属性都属于标志类型的布尔属性,只存在有和没有的区别,没有属性值的概念。
Deprecated 属性用于表示某个类、字段或者方法,已经被程序作者定为不再推荐使用,它可以通过在代码中使用 @deprecated 注释进行设置。
Synthetic 属性代表此字段或者方法并不是由 Java 源码直接产生的,而是由编译器自行添加的,在 JDK 1.5 之后,标识一个类、字段或者方法是编译器自动产生的,也可以设置它们访问标志中的 ACC_SYNTHETIC 标志位,其中最典型的例子就是 Bridge Method。所有由非用户代码产生的类、方法及字段都应当至少设置 Synthetic 属性和 ACC_SYNTHETIC 标志位中的一项,唯一的例外是实例构造器 “<init>” 方法和类构造器 “<clinit>” 方法。
Deprecated 和 Synthetic 属性的结构非常简单,见表 6-26。

其中attribute_length数据项的值必须为0x00000000,因为没有任何属性值需要设置
16.StackMapTable属性
StackMapTable 属性在 JDK 1.6 发布后增加到了 Class 文件规范中,它是一个复杂的变长属性,位于 Code 属性的属性表中。这个属性会在虚拟机类加载的字节码验证阶段被新类型检查验证器(Type Checker)使用,目的在于代替以前比较消耗性能的基于数据流分析的类型推导验证器。
这个类型检查验证器最初来源于 Sheng Liang(听名字似乎是虚拟机团队中的华裔成员)为 Java ME CLDC 实现的字节码验证器。新的验证器在同样能保证 Class 文件合法性的前提下,省略了在运行期通过数据流分析去确认字节码的行为逻辑合法性的步骤,而是在编译阶段将一系列的验证类型(Verification Types)直接记录在 Class 文件之中,通过检查这些验证类型代替了类型推导过程,从而大幅提升了字节码验证的性能。这个验证器在 JDK 1.6 中首次提供,并在 JDK 1.7 中强制代替原本基于类型推断的字节码验证器。关于这个验证器的工作原理,《Java 虚拟机规范(Java SE 7版)》花费了整整 120 页的篇幅来讲解描述,并且分析证明新验证方法的严谨性。
StackMapTable 属性中包含零至多个栈映射帧(Stack Map Frames),每个栈帧映射帧都显示或隐式地代表了一个字节码偏移量,用于表示该执行到该字节码时局部变量表和操作数栈的验证类型。类型检查验证器会通过检查目标方法的局部变量和操作数栈所需要的类型来确定一段字节码指令是否符合逻辑约束。StackMapTable 属性的结构见表 6-27。
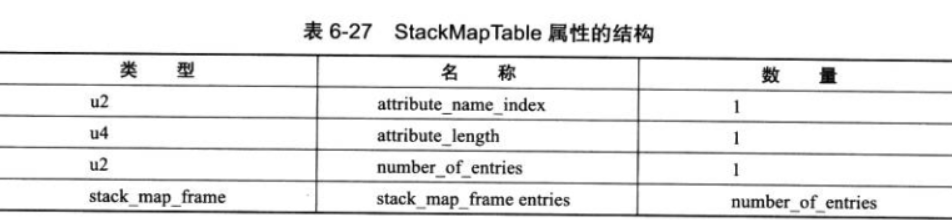
《Java 虚拟机规范(Java SE 7 版)》明确规定:在版本号大于或等于 50.0 的 Class 文件中,如果方法的 Code 属性中没有附带 StackMapTable 属性,那就意味着它带有一个隐式的 StackMap 属性。这个 StackMap 属性的作用等同于 number_of_entries 值为 0 的 StackMapTable 属性。一个方法的 Code 属性最多只能有一个 StackMapTable 属性,否则将抛出 ClassFormatError 异常。
17.Signature属性
Signature 属性在 JDK 1.5 发布后增加到了 Class 文件规范之中,它是一个可选的定长属性,可以出现于类、属性表和方法表结构的属性表中。在 JDK 1.5 中大幅增强了 Java 语言的语法,在此之后,任何类、接口、初始化方法或成员的泛型签名如果包含了类型变量(Type Variables)或参数化类型(Parameterized Types),则 Signature 属性会为它记录泛型签名信息。之所以要专门使用这样一个属性去记录泛型类型,是因为 Java 语言的泛型采用的是擦除法实现的伪泛型,在字节码(Code 属性)中,泛型信息编译(类型变量、参数化类型)之后都通通被擦除掉。使用擦除法的好处是实现简单(主要修改 Javac 编译器,虚拟机内部只做了很少的改动)、非常容易实现 backport,运行期也能够节省一些类型所占的内存空间。但坏处是运行期就无法像 C# 等有真泛型支持的语言那样,将泛型类型与用户定义的普通类型同等对待,例如运行期做反射时无法获得泛型信息。Signature 属性就是为了弥补这个缺陷而增设的,现在 Java 的反射 API 能够获取泛型类型,最终的数据来源也就是这个属性。Signature 属性的结构见表 6-28。

其中 signature_index 项的值必须是一个对常量池的有效索引。常量池在该索引处的项必须是 CONSTANT_Utf8_info 结构,表示类签名、方法类型签名或字段类型签名。如果当前 Signature 属性是类文件的属性,则这个结构表示类签名,如果当前的 Signature 属性是方法表的属性,则这个结构表示方法类型签名,如果当前 Signature 属性是字段表的属性,则这个结构表示字段类型签名。
18.BootstrapMethods属性
BootstrapMethods 属性在 JDK 1.7 发布后增加到了 Class 文件规范之中,它是一个复杂的变长属性,位于类文件的属性表中。这个属性用于保存 invokedynamic 指令引用的引导方法限定符。《Java 虚拟机规范(Java SE 7 版)》规定,如果某个类文件结构的常量池中曾经出现过 CONSTANT_InvokeDynamic_info 类型的常量,那么这个类文件的属性表中必须存在一个明确的 BootstrapMethods 属性,另外,即使 CONSTANT_InvokeDynamic_info 类型的常量在常量池中出现过多次,类文件的属性表中最多也只能有一个 BootstrapMethods 属性。BootstrapMethods 属性与 JSR-292 中的 InvokeDynamic 指令和 java.lang.invoke 包关系非常密切,要介绍这个属性的作用,必须先弄清楚 InvokeDynamic 指令的运作原理,在此先暂时略过。
目前的 javac 暂时无法生成 InvokeDynamic 指令和 BootstrapMethods 属性,必须通过一些非常规的手段才能使用到它们,也许在不就的将来,等 JSR-292 更加成熟一些,这种状况就会改变。BootstrapMethods 属性的结构见表 6-29。
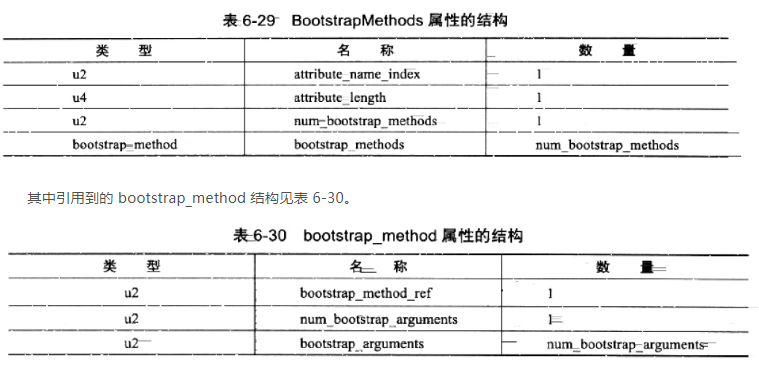
BootstrapMethods 属性中,num_bootstrap_methods 项的值给出了 bootstrap_methods[] 数组中的引导方法限定符的数量。而 bootstrap_methods[] 数组的每个成员包含了一个指向常量池 CONSTANT_MethodHandle 结构的索引值,它代表了一个引导方法,还包含了这个引导方法静态参数uDelay序列(可能为空)。bootstrap_methods[]数组中的每个成员必须包含以下 3 项内容。
- bootstrap_method_ref:bootstrap_method_ref 项的值必须是一个对常量池的有效索引。常量池在该索引处的值必须是一个 CONSTANT_MethodHandle_info 结构。
- num_bootstrap_arguments:num_bootstrap_arguments 项的值给出了 bootstrap_arguments[] 数组成员的数量。
- bootstrap_arguments[]:bootstrap_arguments[] 数组的每个成员必须是一个对常量池的有效索引。常量池在该索引处必须是下列结构之一:CONSTANT_String_info、CONSTANT_Class_info、CONSTANT_Integer_info、CONSTANT_Long_info、CONSTANT_Float_info、CONSTANT_Double_info、CONSTANT_MethodHandle_info 或 CONSTANT_MethodType_info。
转载地址:http://synax.baihongyu.com/